
#0. 금속착물촉매 연구자들의 고민, 노가다를 계속 해야하는가?
당신이 어떤 촉매를 사용한다고 했을 때, 이 촉매가 슬쩍 테스트해보니 꽤 좋아보인다. 마구 논문을 써서 자랑을 하고 싶다.근데 이게 얼마나 좋은지를 어떻게 보여줘야 잘 보여줬다고 소문이 날까?
최근까지 연구자들은 특정 반응에 대해서 촉매 활성을 보이는 경우 구조가 다른 많은 substrate를 반응시켜서 '봐라 우리가 이거이거 테스트 해봤는데 상관없이 다들 괜찮게 반응해!' 라고 자랑하는 식이다. 마치 제약회사에서 임상 단계를 거쳐 올라오면서 '자 세포에서 효과있고, 조직에서 효과있고, 쥐, 원숭이, 사람 까지 테스트 해봤는데 다 잘돼!' 하는 것과 비슷한 논리다. 하지만 여기서 나타나는 치명적인 단점은 시간이 무지하게 많이 든다는 것이다.
#1. 머신러닝의 등장
머신러닝의 등장으로 화학계에서도 흥미로운 연구결과들이 많이 나오고 있다. 특히 금속착물을 연구하는 나 같은 사람은 착물이 만들어질지 (안정한지), 만들어졌으면 그 착물의 반응성이 어떨지, 이를 토대로 한 일반화를 시키기 위해서 정말 많은 수의 리간드와 substrate들을 테스트하곤 한다. 가령 우리 촉매가 어떤 특정한 촉매반응을 선택적으로 잘 일으키는 것을 확인했어요! 라는 결과의 논문을 낸다고 했을 때 중요하게 보는 데이터가 그 반응에서 얻은 수득률 (Yield), 그리고 Functional group tolerance이다 (물론 논문에 따라서 enantioselectivity 등이 추가되기도 한다). 후자가 의미하는 바는 내가 원하는 부분의 작용기에 대해서 얼마나 선택적으로 반응시킬 수 있는지에 대한 지표가 된다. 다른 functional group이 달려있어도 높은 yield나 선택성을 유지할 수 있는지를 보여줄 수 있기 때문이다.
이를 보여주기 위해서 논문의 TOC (table of contents, or graphical abstract)에 몇 개의 substrate를 테스트했는지 자랑스럽게 적어서 보여주곤 한다.
그래서 이런 논문들을 보면 SI (Supporting information)만 수백페이지에 달하곤 하는데, 각 페이지마다 사용한 substrate를 합성한 방법, characterization data (주로 NMR)가 담겨있기 때문이다. 이런 경우에 publish하기에 정말로 많은 수고가 들어간다는 것을 부정할 수 없다. 다른 회사에서 사다가 쓸 수 있는 정도면 그냥 같은 반응 한 번 더 돌린다고 생각하겠으나, 그렇지 않은 substrate를 생각하는 경우 (이런 경우 더 novelty가 올라가기에) 직접 substrate를 만들어서 test하고 되는지 안되는지를 테스트하기에 시간이 오래걸리기는 부지기수다.
지금 비록 catalysis에 대해서만 소개하긴 했지만, 많은 화학 반응을 시도하기 전에 될지 안될지, Yield가 얼마나 될지를 예측할 수 있다면 상당한 시간과 노력을 줄일 수 있을 것이다.
#2. Pd(I)-dimer가 만들어질지 Machine learning으로 예측이 가능하겠니?
그래서 이런 고민을 타파하기 위해 머신러닝 연구가 화학계에도 도입되고 있는데, 흥미롭게 봤던 두 논문을 소개해볼까 한다. 첫 번째는 Pd(I) dimer complex를 머신러닝을 통해서 예측하고 만들어낸 논문이다.
https://www.science.org/doi/10.1126/science.abj0999
Pd(I)은 Pd(II)만큼 흔하지 않고, 특히나 dimer는 일부러 만들려고 해도 다양한 변수들 때문에 만들기 쉽지않은 착물인데, (여태까지 네 개의 Pd(I)-dimer만 보고됨) 기존에 사용되고 있던 여러 리간드들의 여러 특성들을 변수화 시킨다음 지도를 그리듯이 배치하면 어떤 경향성을 확인할 수 있고, 여기서 Pd(I)-dimer가 나온 리간드의 특성과 연관지으면 아직 보고되지 않은 리간드 중에서 어떤 것이 Pd(I)-dimer를 만들 수 있을지 예측이 가능하다는 것이 이 논문의 골자이다.
다양한 변수를 machine learning 시켜서 자 이걸 네 나름의 기준으로 분류를 하는데, 6개의 그룹으로 (k=6) 나눠봐! 했더니 네 여깄습니다! 하고 C0 - C5까지 나눠서 아래와 같이 보여줬다.
그리고 기존에 보고된 Pd(I)-dimer가 있는 그룹 두개가 C3, C0에 있어서 여기서 예측한 리간드들 중 8개를 합성해서 (혹은 사서) Pd(I)-dimer가 만들어지나 봤더니,
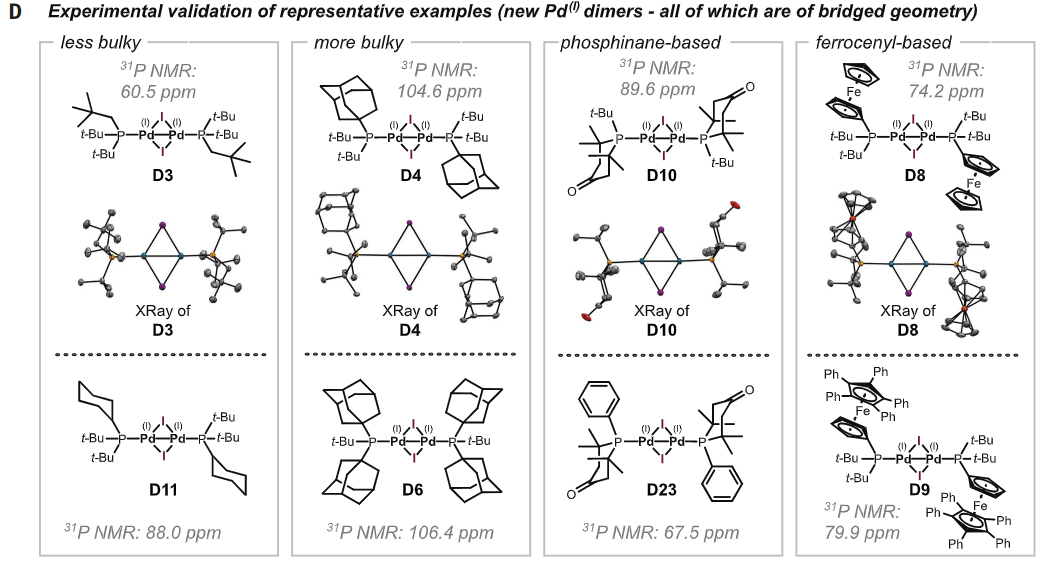
오 이게 크리스탈도 만들어지고 진짜 되더라! 하는 내용이다. 굳이 피똥싸면서 이 리간드 저 리간드 시도해보면서 비싼 Pd 소비할 필요 없이 (크리스탈 제발 커라! 라고 기도할 필요도 없이), 어 예측해보니까 되네? 하면서 만들면 턱 만들어지니 이 얼마나 좋은 기술의 발전인가!
#3. 어떤 substrate가 높은 yield를 보일지 예측해볼래?
다른 논문은 착물 만들기 말고 어떤 substrate가 높은 yield를 보일지에 대한 내용의 논문이다. 많은 수의 논문들이 Ar-X를 substrate로 많이 사용하는데, 그들이 각자 촉매에 yield가 잘 나오는 것들만 보고를 보통 하다보니 세상에 정말 많은 Ar-X (특히 Br) substrate가 보고되게 되었고, 이것은 결국 Ar-Br 테스트를 하려는 다른 과학자들이 기존에 나온 논문들을 봐도 내가 생각한 이 Ar-Br이 잘 먹힐지에 대해 일반화 시킬 수 없다는 단점이 있다.
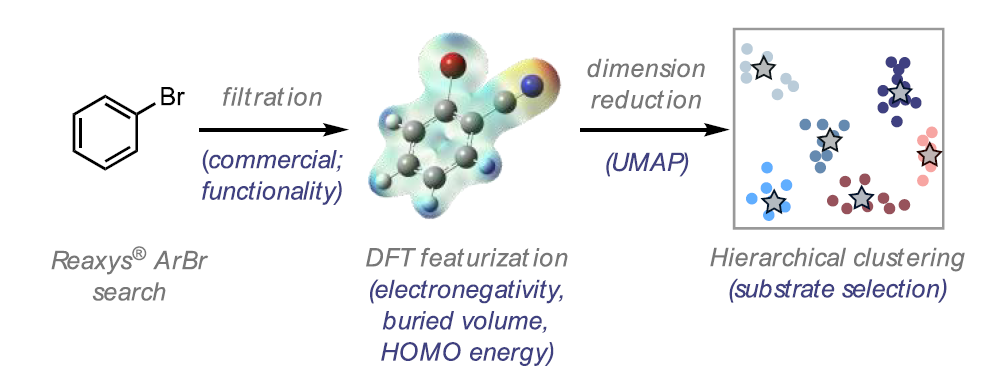
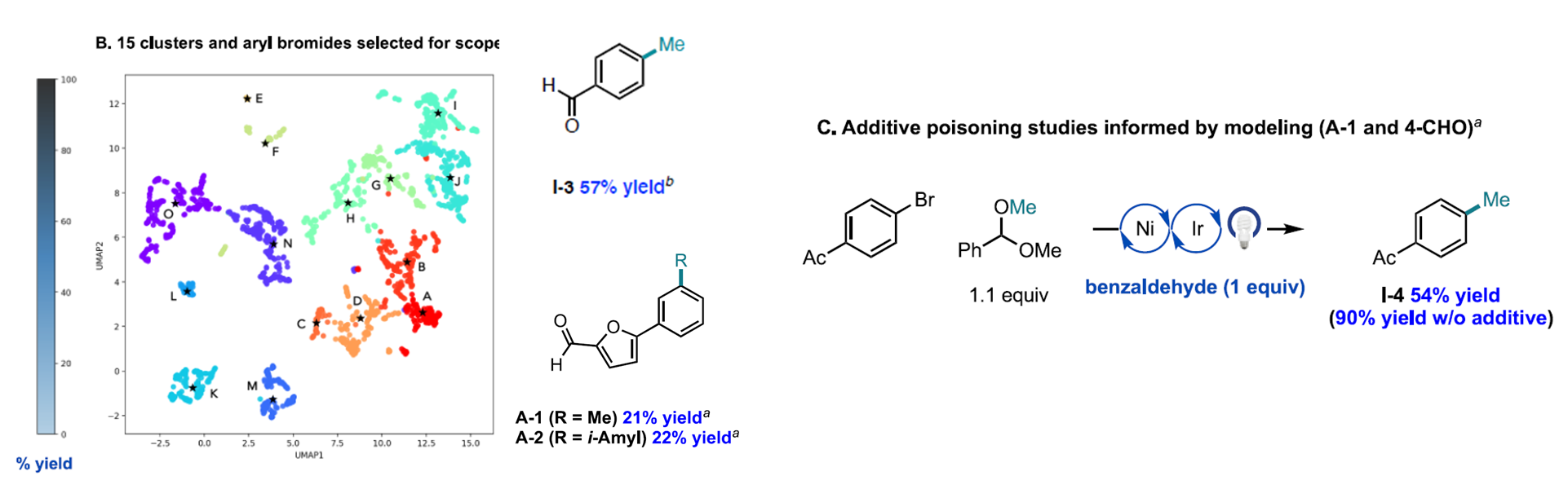
이를 위해 이 논문에서 machine learning을 했는데, 기존에 보고된 70만 개 가량의 Ar-Br에서 Ni-photoredox catalysis로 보고된 Ar-Br substrate 2600개를 추리고 이들을 이전 논문처럼 어떤 기준에 의해서 나눈 과정을 거쳤다.
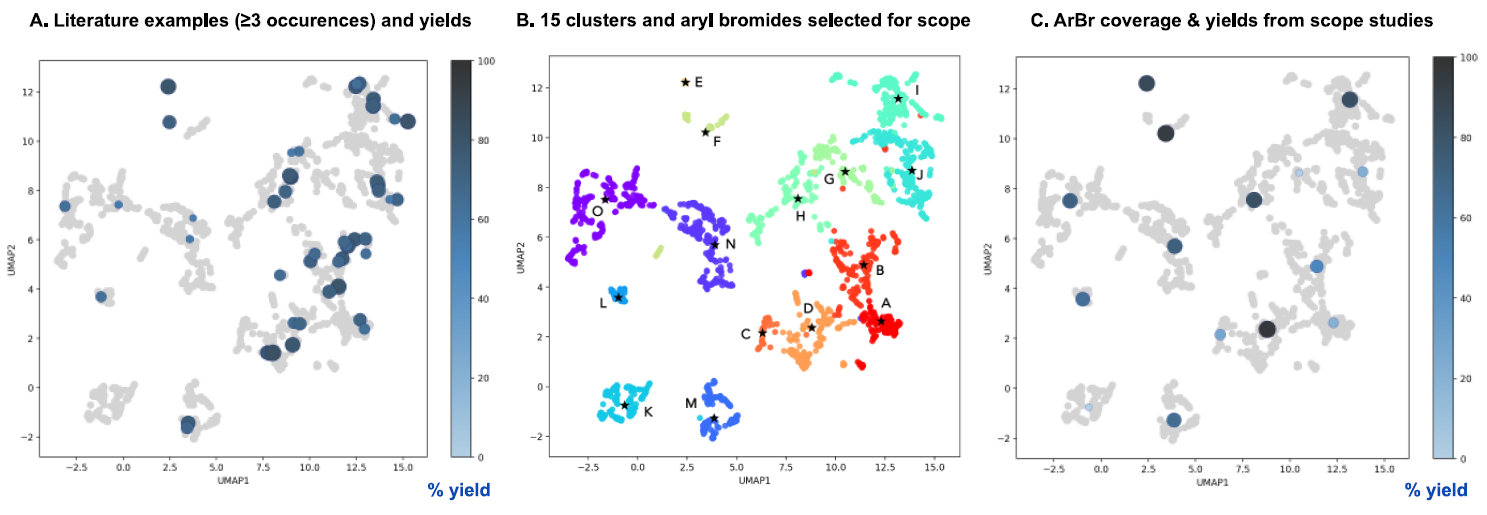
그리고 이들 클러스터에서 뽑은 대표적인 substrate로 실험을 진행 해보니, 실제 논문에 보고된 논문과 비슷한 yield가 나오더라! 하는 것이 첫 번째 포인트.
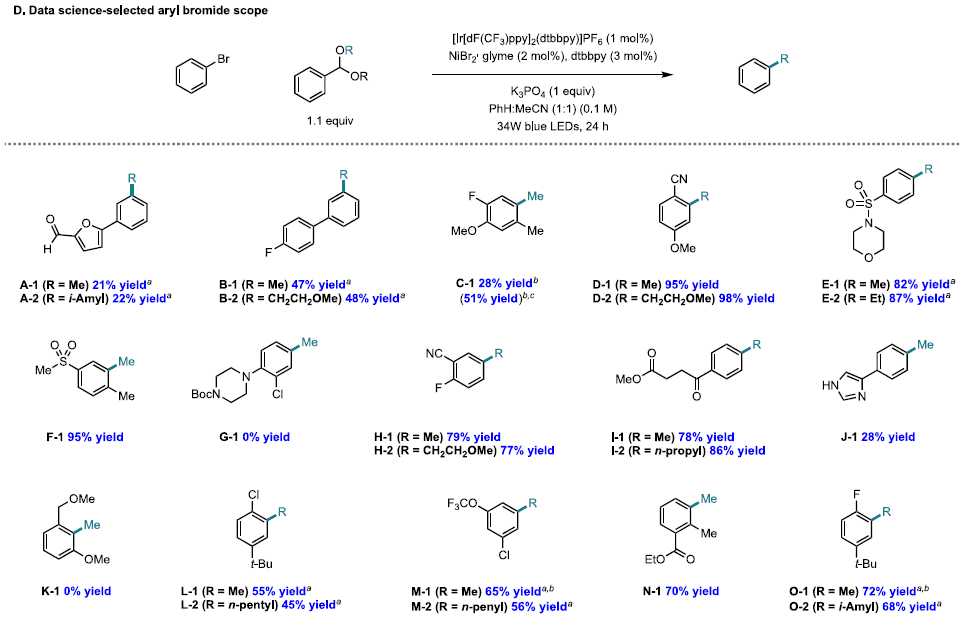
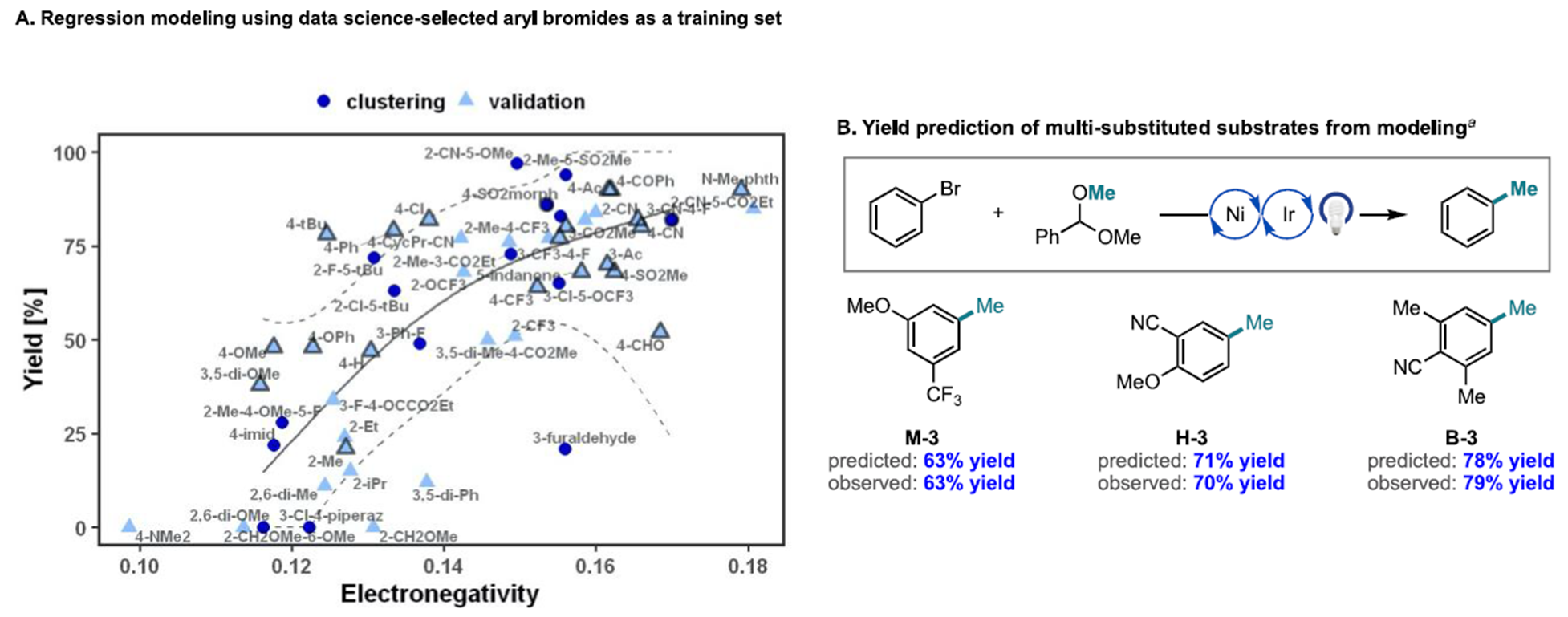
그 다음에는 machine learning을 통해서 이걸 한개의 변수만으로 분류한다면 뭐가 제일 좋겠니? 하니 electronegativity가 가장 좋겠네요! 하길래 이걸로 분류를 해보았다. 여기서 예측한 substrate의 yield와 실제로 실험으로 얻은 yield를 비교해보았더니 위 그림의 오른쪽처럼 상당히 유사한 yield가 나왔다! 라는 걸 보고하게 된 논문이다.
#4. 그렇다면, Machine learning은 신인가? 결국 모든 화학계의 문제를 해결해 버리는건가?!
물론 여기서 지적하는 하나의 문제점은, 항상 이것이 맞진 않다는 것이다. 해당 시스템에서는 만족할지 모르나, 모든 반응이 electronegativity 변수 하나로만 일관된 반응성을 보이지는 않는다는 것이 문제다.
실제로 이들이 확인한 문제점은 electronegativity만으로는 설명되지 않는 낮은 yield product가 나타날 수 있다는 것이다 (external effect). 이 논문에서는 aldehyde functional group을 가진 Ar-Br이 높은 yield를 보일 것으로 예측했으나, 실제로는 그렇지 않았고, 그 이유가 aldehyde group이 반응을 방해했기 때문이다라는 것을 실험적으로 보였다. 즉, 어느정도 일반적인 데이터에는 맞을 수 있으나, 특정한 요인에 의해서 (여기서의 aldehyde group의 존재여부처럼) 반응성에 차이가 크게 나타날 수 있음을 시사하고 있다.
https://pubs.acs.org/doi/pdf/10.1021/jacs.1c12005
또한 다른 논문에서 지적하는바, 아직 이 machine learning을 적용하기에 많은 난관이 있다는 것이다.
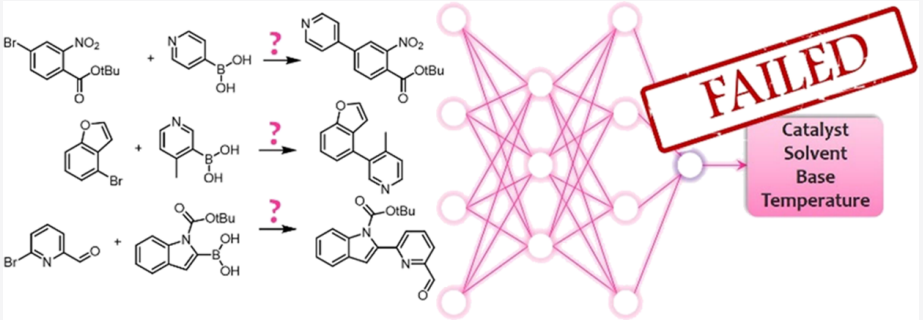
이 논문에서 저자들은 Suzuki cross-coupling reaction에 필요한 여러 반응조건들 중, 어떤 것이 최적의 yield를 보일 것인지에 대해서 수 많은 논문 결과들을 토대로 machine learning을 시켰으나, 성공적이지 못했다는 결과를 보여주었다. 자세한 내용은 나도 machine learning을 정확히 아는 것이 아닌 관계로 설명은 못하겠으나, 지금까지의 결과에서 machine learning과 화학계의 콜라보레이션은 시너지를 얻는 단계 정도인 것 같다.
중간중간 보이는 machine learning으로 부터 얻은 좋은 결과들이 쌓이고 쌓이다보면 어떤 것은 machine learning으로 예측이 잘 되고 어떤 것은 덜 되는 식으로 논문들이 쌓여나가고 또 거기서 많은 정보가 쌓이다보면 계속해서 발전할 수 있는, 결국에 많은 시간이 지나면 굳이 실험 안해도 바로 타겟물질을 만들어버릴 수 있는 시대가 열리지 않을까 조심스럽게 예상해본다!
'화학 > Chemistry' 카테고리의 다른 글
| Elemental Analysis (EA, 원소분석)는 과연 Purity 확인에 가장 좋은 분석 방법일까? (0) | 2022.07.02 |
|---|---|
| 논문은 어쩌다 철회되나? 철회된 논문을 모아서 정리해놓은 사이트, Retraction Watch (0) | 2022.05.03 |
| 콜라엔 왜 카페인을 집어 넣는걸까? (0) | 2022.03.12 |
| DFT - Spin density란? (0) | 2022.02.03 |
| Chemissian 프로그램 이것저것 활용하는 법 간단 요약 (0) | 2022.02.01 |


